Hi everyone! My name is Ethan Trokie and I’m a rising junior at Northwestern University and I’m studying computer engineering. I’m currently working with Pete Beckman, Zeeshan Nadir, and Nicola Ferrier as part of the Waggle research project in the Mathematics and Computer Science Division. The goal of the Waggle research project is to deploy an array of sensors all over Chicago to detect different things such as air quality, noise, and other factors. The data that will be collected will become open source so that scientists and policy makers can work together to make new discoveries and informed policy. What waggle is doing is a massive shift from previous environmental science data collection techniques. Previously scientists used very large sensors that are very expensive and precise but very sparse. Waggle is trying to move towards small sensors that are much less expensive and slightly less precise, but there are a lot more of them. This new technique can give scientist much more localized data which can lead to novel discoveries.
What I’m working on specifically is machine learning and computer vision that runs locally on the Waggle nodes, which are what we call the containers which hold all of the sensors. My task is to use a camera that is on the Waggle node to detect flooding in the streets using just the camera. This can help the city of Chicago get data where flooding commonly happens and can help then clean up the flooding faster by knowing where the actual flooding is happening.
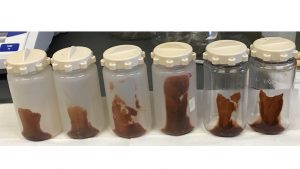
I’ve spent this summer so far learning what machine learning is and how to use it to detect water. What makes my project interesting is the fact that water is difficult to detect because water doesn’t have a shape or color, so it’s difficult to tell the computer exactly what to look for. But there has been some research into detecting moving water and I’ve created a good detector in python by just looking at a short video. Below are two sample videos that my program has classified. The center image is a frame from the video, the left most image is the mask over the non-water that my program created, and the right most image is the mask over the actual image.






Next I am going to improve this classifier to become even more accurate. In addition, right now it only really works on moving water, but I hope to be able to expand this machine learning to be able to classify standing water as well. I’m excited to get more acquainted with different types of machine learning algorithms and hopefully see my code run on a waggle node in Chicago and see if it creates positive impact on Chicago.
Month: July 2017
Data Preprocessing for Predictive Models
Greetings, I am Connor Moen! I’m a rising sophomore at Northwestern University studying computer science and environmental engineering. This summer I am working under Dr. Stefan Wild at Argonne National Laboratory, where I am assisting him with developing accurate flood prediction models for the City of Chicago. The goal of these models is to analyze weather conditions and soil moisture on a block-by-block basis (or, for the time being, where sensors are installed) and then determine if flooding will occur. This knowledge can be used to notify homeowners in flood-prone regions to prepare for flooding, thereby minimizing property damage and disruption after heavy storms.
I have spent much of the summer collecting vast amounts of data from the Chicago Data Portal and UChicago’s Thoreau Sensor Network, preprocessing it using the AWK programming language, and working to visualize it in MATLAB. Below is a MATLAB plot showing the Volumetric Water Content for all sensors in the Thoreau Network over the past few months.
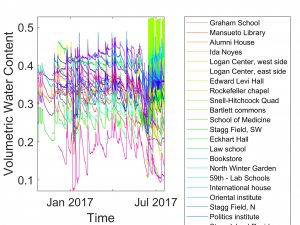
The future of the project will involve qualitatively describing the trends we see in our data (for example, might the uncharacteristic behavior seen in a number of sensors after mid-June be caused by an outside factor such as sprinklers?), and then writing, testing, and refining the predictive models. Personally, I am most excited to dive into these predictive models; I am fascinated by the idea of combining environmental sensing with machine learning in order to directly help those living in my neighboring city.
Machine Learning and the Power Flow Equations
Hello! My name is Wesley Chan, and I’m a rising junior studying computer science and economics at Northwestern University. This summer I’m interning at Argonne in the CEEESA (Center for Energy, Environmental, and Economic Systems Analysis) division. I’m working with my PI, Dr. Daniel Molzahn, to research the topic of worst-case errors in linearizations of the power flow equations for electric power systems.
What does that even mean? Well to break it down, steady-state mathematical models of electric power grids are formulated as systems of nonlinear “power flow” equations. The power flow equations form the key constraints in many optimization problems used to ensure reliable and economically efficient operation of electric power grids. However, the nonlinearities in the power flow equations result in challenging optimization problems. In many practical applications, such as electricity markets, linear approximations of the power flow equations are used in order to obtain tractable optimization problems. These linear approximations induce errors in the solutions of the optimization problems relative to the nonlinear power flow equations. In addition, characterizing the accuracies of the power flow approximations has proved extremely challenging and test-case dependent.
As a result, the research effort Dr. Molzahn is trying to carry out aims to develop new characterizations of the problem features that yield large errors in the power flow linearizations through utilizing a variety of data analysis and machine learning methods. If accurate and reliable characterizations can be made, it would allow power system operators to identify when the results of their optimization problems may be erroneous, thus improving the reliability and economic efficiency of electric power grids.
So what I’ve been working on is building and implementing a number of different machine learning algorithms in order to help accomplish that. One of those algorithms I’ve developed is a multilayer perception neural network using Python and Tensorflow. Using the IEEE 14 bus test case, we were able generate actual optimization results for an AC and DC case using Matlab and Matpower. With the data from those results, I was able to create a dataset with enough samples and features to train on. I would use the neural network model to predict the difference between optimal cost generated from the AC model vs the DC model. The neural network takes in the data, splits it into training and testing sets, and then using forward and back propagation, will iterate through a specified number of epochs, and learn the data, minimizing error on each epoch using stochastic gradient descent.
Because I am still relatively new to machine learning and Tensorflow, I ran into some difficulties trying to build the model. For close to a full week, there was a bug in my code that was yielding an uncharacteristically large error no matter how many epochs I trained the model on. I tried countless different things in order to remedy this. Finally, I realized the bug lied in the fact that I was “normalizing” my input data (a technique I read somewhere online to help deal with varying scales in the features) when I should have been “scaling” it. A simple one word fix helped change my results drastically. With that change, my model went from making predictions with a mean squared error of 600, to a mean squared error of 0.8. Given that the range of optimal cost difference was between 300-600 dollars, a mean squared error of 0.8 was less than a 0.01% average error.
Following that, I’m now working on generalizing the neural network model to predict other relevant aspects such as the power generation from each bus, and the power generation cost of each bus. I’m excited to gain more hands on experience with machine learning, to work more on this topic, and to see what kind of results we can get!
Toward an Artificial Neuron
Hello, I am AnnElise Hardy, a biomedical engineer at Northwestern University, ‘19, and I am working with Elena Rozhkova in the Nanoscience and Technologies Division as part of the larger Artificial Neuron Group led by Chris Fry. The group is working towards creating an artificial neuron, a bio-inspired assembly. The proposed design will place light activated transmembrane proton pumps either taken from the archaea Halobacterium halobium, or created synthetically, on a gold compartmentalized structure in order to create an assembly that can mimic the low-voltage ion flow of a neuron. These “protocells” are the first step in creating an artificial neuron to then be used in neuromorphic computing systems.
Currently, I am working to isolate the proton pumps, each attempt takes a few days and a couple more days to grow more archaea. Our first few attempts were not successful, but we are adapting our procedure to address what we think the problems are. For example, we have increased the amount we distress the cells in order to break up the membranes more. If we cannot achieve isolation directly from the archaea, we will then move to create the pumps in a cell-free synthesis, which Dr. Rozhkova has shown here. The benefit of cell-free synthesis lies in the removal of time- and labor-intensive culturing of the archaea, limiting the issues we have seen in harvesting the pumps at the optimal point of cell growth.