Hello! My name is Sarah O’Brien and I’m a rising Junior and Computer Science major at Northwestern University. I’m working with Maria Chan at Argonne and Eric Schwenker (PhD candidate in Materials Science and Engineering) at Northwestern on developing an automated process to create large training sets for image-based machine learning models.
Having large datasets with labeled classes or features is vital for training deep neural networks – and large datasets, particularly in the field of materials science, are often not publicly available. As such, without an automated workflow, organizing and labeling large sets of images is extremely time consuming and needs to be done manually each time we have a new problem to solve with machine learning.
This summer, we developed an Image Pre-processing Workflow to produce training and test data for our machine learning model. We first obtain many figures and captions from the scientific literature and use string parsing in the caption to decide if a figure is “compound,” i.e. made up of multiple subfigures. If it is, we extract each individual sub-figure with a figure separation tool developed by researchers at Indiana University2. Below is an example of the compound figure separation process.
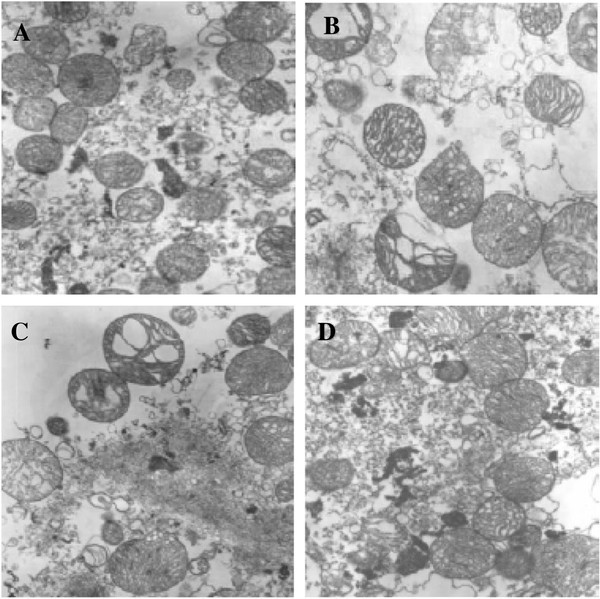
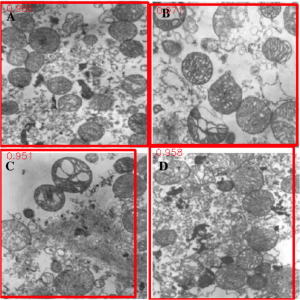
TOP: Original Compound Figure from literature1; BOTTOM: Output of Figure Separation tool
Once we have a set of many separated figures, we decide if each is useful for our training set or not; for example, to create a set of microscopy images we trained a Convolutional Neural Network to create a binary microscopy image/non-microscopy image classifier. We trained this classifier on 960 total hand-labeled images (480 microscopy images and 480 non-microscopy images) and used two approaches: transfer learning and training from scratch. Both methods yielded classifiers with about 94% accuracy using ten-fold cross validation; we are working on making this classifier even more accurate by fine-tuning the models. Together with the figure separator, this trained classifier now allows us access to a large number of individual microscopy images for our future work on training a deep learning model.
My work on this project is important because a working image pre-processing workflow is essential for training a machine learning model. The data pre-processing stage of a machine learning task is often quite time consuming, so to be able to complete the stage automatically will offer us the ability to extract a large amount of information from a collection of images in a relatively short time, and therefore enable automated interpretation and understanding of materials through microscopy.
I’m excited for the future of this project and to see this workflow’s output in action building deep learning tools that will advance scientific collaboration. Special thanks to Dr. Maria Chan, Dr. Jennifer Dunn, and Eric Schwenker for mentoring me this summer.
References:
1: https://media.springernature.com/lw785/springer-static/image/art%3A10.1186%2F2047-9158-1-16/MediaObjects/40035_2012_Article_15_Fig2_HTML.jpg
2: S. Tsutsui, D. Crandall, “A Data Driven Approach for Compound Figure Separation Using Convolutional Neural Networks”, ICDAR, 2017.