Hello! My name is Nicole Camburn and I am a rising senior studying Biomedical Engineering at Northwestern University. This summer I am working with Dr. Marta Garcia Martinez, Computational Scientist at Argonne National Laboratory, with the goal of using machine learning and learning-free methods to perform automatic segmentation of medical images. The ultimate objective is to avoid manually segmenting large datasets (a time consuming and tedious process) in order to perform calculations and generate 3D reconstructions. Furthermore, the ability to automatically segment all of the bone and muscle in the upper arm would allow for targeted rehabilitation therapies to be designed based on structural features.
This past year, I did research with Dr. Wendy Murray at Shirley Ryan AbilityLab, and I was looking at how inter-limb differences in stroke patients compared to healthy patients. Previous work done in Dr. Murray’s laboratory has shown that optimal fascicle length is substantially shorter in the paretic limb of stroke patients [1], so my research focused on whether bone changes occur as well, specifically in the humerus. In order to calculate bone volume and length, it was necessary to manually segment the humerus from sets of patient MRI images. Generally speaking, segmentation is the process of separating an image into a set of regions. When this is done manually, an operator hand draws outlines around every object of interest, one z-slice at a time.
Dr. Murray and her collaborator from North Carolina State University, Dr. Katherine Saul, both study upper limb biomechanics, and some of their previous research has involved using manual segmentations to investigate how muscle volume varies in different age groups. Figure 1 shows what one fully segmented z-slice looks like in relation to the original MRI image, as well as how these segmentations can be used to create a 3D rendering.
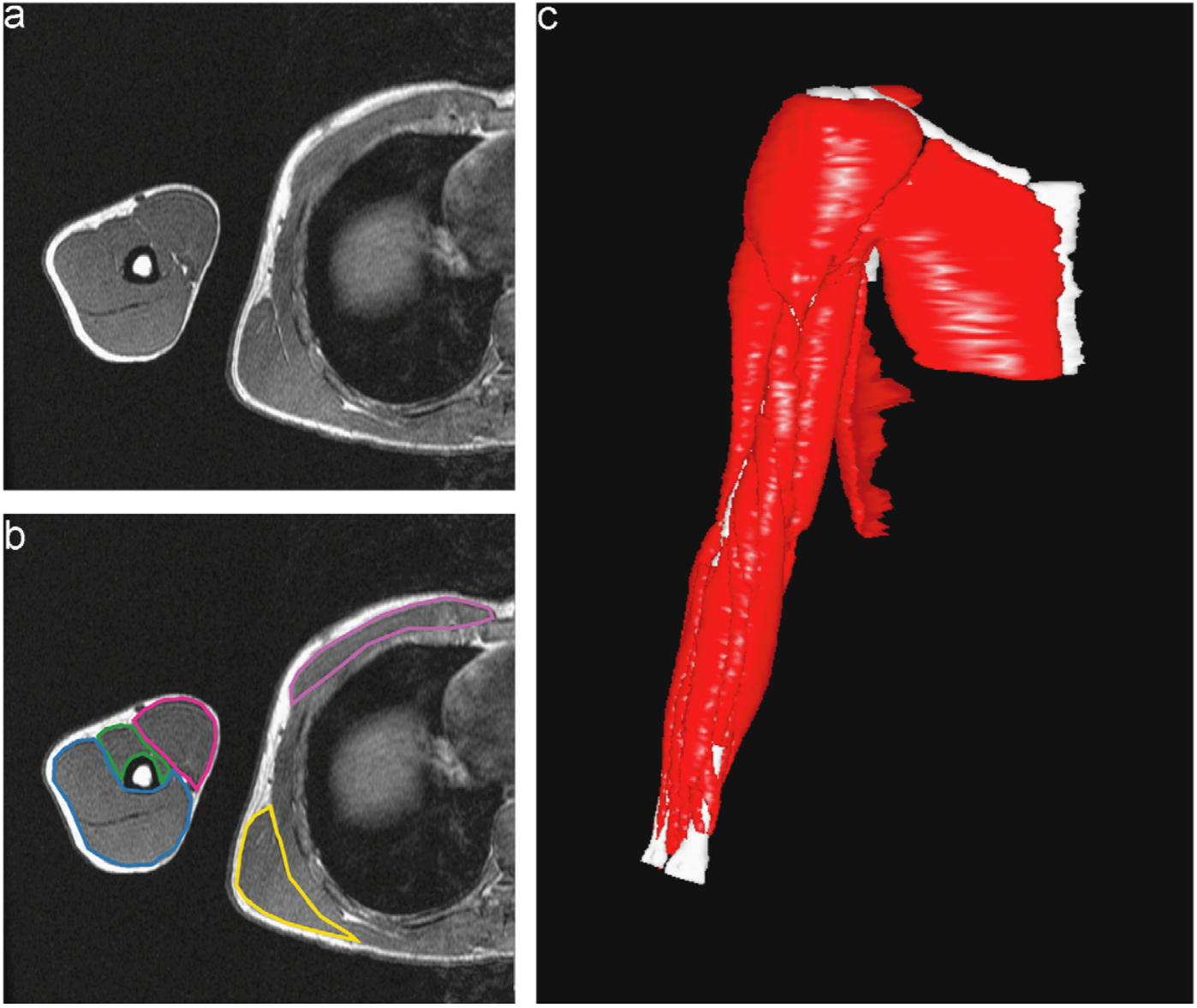
Figure 1: Manually Segmented Features and 3D Reconstruction [2].
In one study, this procedure was done for 32 muscles in 18 different patients [3], and it took around 20 hours for a skilled operator to segment the muscles for one patient. This adds up to nearly 400 hours of manual work for this study alone, supporting the desire to find a more efficient method to perform the segmentation.
For my project so far, I have focused on a single MRI scan for one patient, which can be seen in the following video. This scan contains the patient’s torso as well as a portion of the arm, and 12 muscles were previously manually segmented in their entirety. The humerus was never segmented for this dataset, but because there is higher contrast between the bone and surrounding muscle as compared to between adjacent muscles, it is a good candidate for threshold-based segmenting techniques.
Figure 2: Dataset Video.
One tool I have tested on the MRI images to isolate the humerus is called the Flexible Learning-free Reconstruction of Imaged Neural volumes pipeline, also known as FLoRIN. FLoRIN is an automatic segmentation tool that uses a novel thresholding algorithm called N-Dimensional Neighborhood Thresholding (NDNT) to identify microstructures within grayscale images [4]. It does this by looking at groups of pixels known as neighborhoods, and it makes each pixel either white or black depending on if its intensity is less than or greater than a proportion of the neighborhood average. FLoRIN also uses volumetric context by considering information from the slices surrounding the neighborhood.
FLoRIN’s threshold is set to separate light and dark features, so the humerus must be segmented in two pieces because the hard, outer portion shows up as black on the scan while the inner part appears white. To generate the middle image in Figure 3, I inverted the set of MRI images and fed them through the FLoRIN pipeline, adjusting the threshold until the inner bone was distinct from the rest of the image. Next, I used FLoRIN to separate the three largest connected components, which are the red, blue, and yellow objects in the rightmost image. After sorting the connected components by area, I was able to isolate the inner part of the humerus, which is represented by the yellow component.
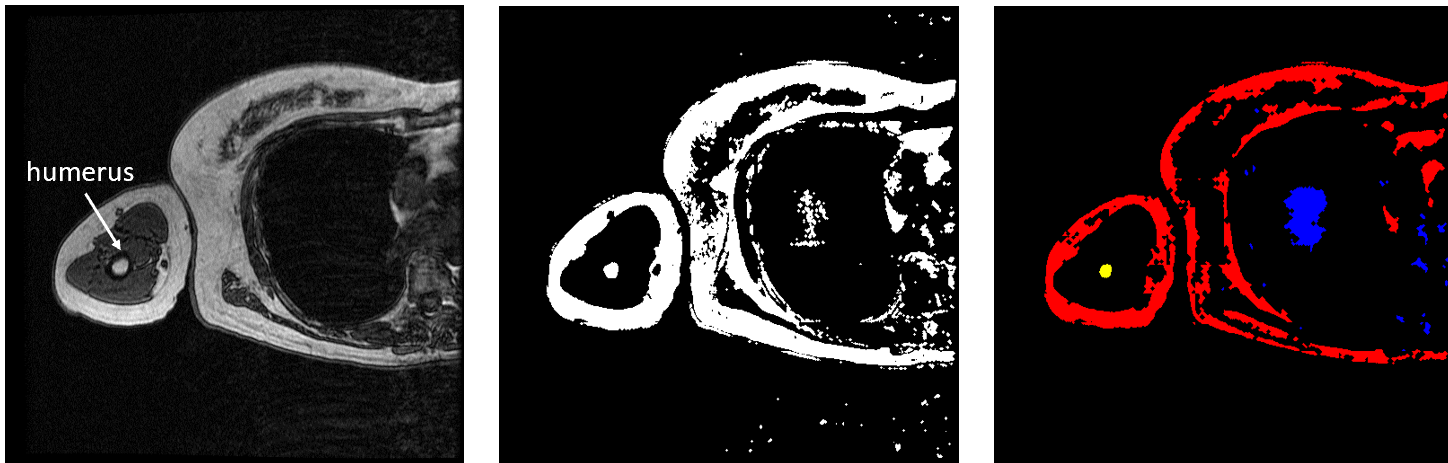 Figure 3: Original Image (left). Light Features as One Object (middle). Three Connected Components (right).
Figure 3: Original Image (left). Light Features as One Object (middle). Three Connected Components (right).
Another method I explored throughout my research was the use of a Convolutional Neural Network (CNN) to perform semantic segmentation, the process of assigning a class label to every pixel in an image. The script used to do this was inherited from Bo Lei of Carnegie Mellon University and was adapted to have additional functionality. To train a CNN to perform semantic segmentation, a set of the original images along with ground truth labels must be provided. A ground truth label is the actual answer in which each object in the image is properly classified, and this process is often done manually. However, because a network can be applied to a larger image set than it was trained on, manually segmenting the labels requires much less time as compared to manually segmenting an entire dataset. The CNN approximates a function that relates an input (the training images) to an output (the labels). The network parameters are initialized with random values and as it is trained, the values are updated to minimize the error. One complete pass through the training data is called an epoch, and at the end of each epoch the model performs validation with another set of images. Validation is the process in which the CNN tests itself to see how well it performs segmentation as it is tuning the parameters. Finally, after training is complete, the model can be tested on a third set of images that it has never seen before to give an unbiased assessment of its performance.
As stated previously, threshold-based techniques cannot be used to segment the individual arm muscles due to the lack of contrast, so I employed machine learning methods instead. For simplicity, I decided to start by training a network to only recognize one muscle class. I chose to begin with the bicep because of all of the upper arm muscles that have been segmented in this scan, it has the most distinct boundaries. This means that the network is being trained to identify two classes total, which are the bicep class and the background class. For this patient, there were 71 images containing the bicep, and I dedicated 59 for training, 10 for validation, and 2 for testing. For each set, I selected images from the MRI stack in approximately equally spaced intervals so that they each contained images that were representative of multiple sections of the bicep. After training a network using the SegNet architecture and the hyperparameters seen in Table 1, I evaluated its performance by segmenting the two full-size test images.
 Table 1: Network Hyperparameters.
Table 1: Network Hyperparameters.
I created overlays of the CNN output segmentations and ground truth labels, and this can be seen below next to the original MRI image for the first test image. The white in the overlay corresponds with correctly identified bicep pixels, the green corresponds with false positive pixels, and the pink corresponds with false negative pixels. The overlay shows that the network mostly oversegmented the bicep, adding pixels where they should not be.
 Figure 4: Test Image 1 (far left). Ground Truth Label (middle left). NN Output (middle right). Overlay (far right).
Figure 4: Test Image 1 (far left). Ground Truth Label (middle left). NN Output (middle right). Overlay (far right).
In addition to assessing the network’s performance visually, I also calculated two metrics, which are the bicep Intersection over Union (IoU) and boundary F1 score. Bicep IoU is calculated by dividing the number of correctly identified bicep pixels in the CNN segmentation by the total bicep pixels present in both the ground truth label and the prediction. Boundary F1 score indicates what percentage of the segmented bicep boundary is within a specified distance (two pixels in our case) of where it is in the ground truth label. This network had a bicep IoU of 64.1%, and average boundary F1 score of 23.8%.
After training a network on the full-size images, I decided to try training on a set of cropped images to see if this would improve segmentation. The theory behind this test was to remove the majority of the torso from the scan because it contains features that have similar grayscale level as the bicep. This was done using a MATLAB script that takes a 250×250 pixel area from the same images used previously to train, validate, and test. This script as well as the one used to create the overlays were both inherited from Dr. Tiberiu Stan of Northwestern University. The coordinates were chosen so that the images could be cropped as much as possible without excluding any bicep pixels, which is portrayed in the set of videos below.
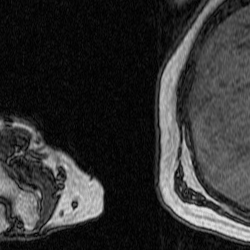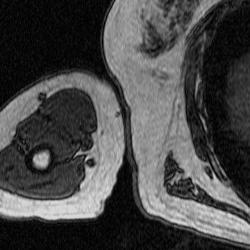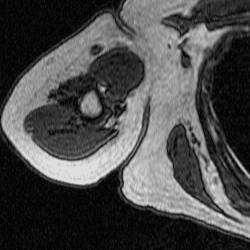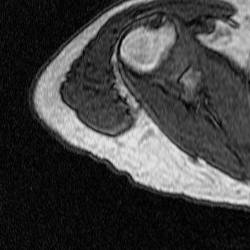

Figure 5: Cropped Images (left) and Labels (right).
When comparing both networks’ bicep segmentations for the two test images, it is apparent that the network trained on cropped images predicted cleaner bicep boundaries. This is especially noticeable in the second test image because the green false positive pixels are in a much more uniform area surrounding the bicep. However, the network trained on cropped images had slightly a lower bicep IoU and boundary F1 score, which were 62.9% and 18.2% respectively. The cropped network also confused a feature in the torso with the bicep, which was not an issue for the network trained on full-size images.
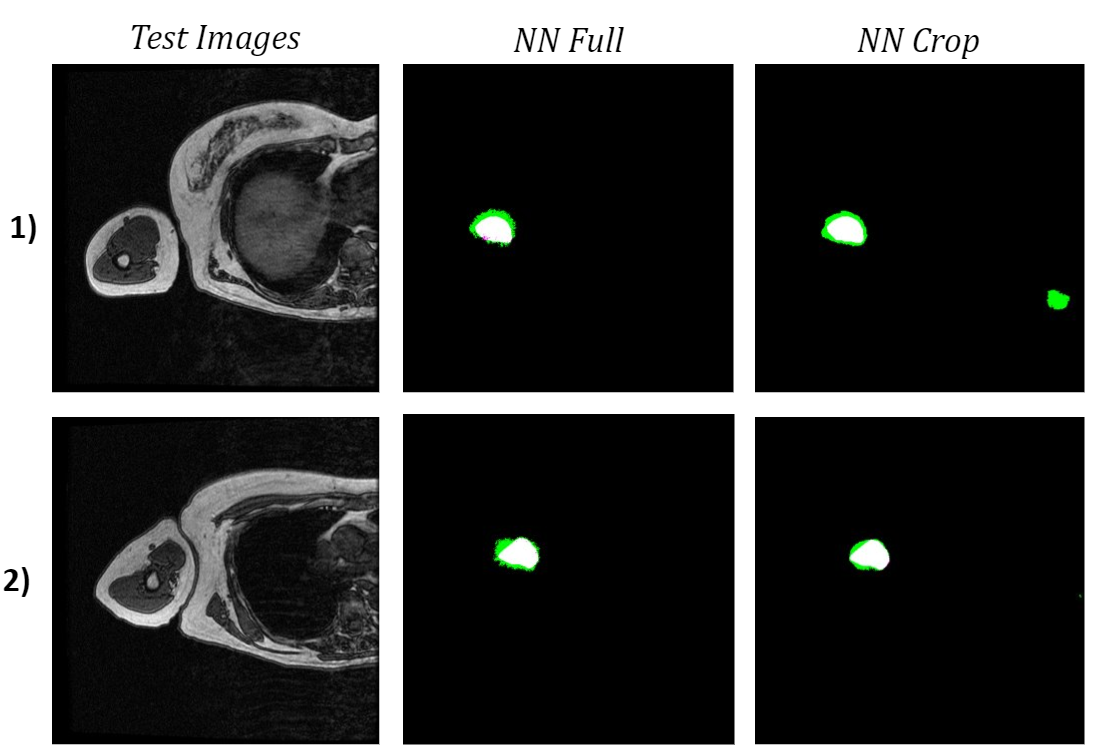
Figure 6: Comparison of Test Image Segmentations.
To see how the networks performed on a more diverse sample of MRI slices, I tested them both on the 10 validation images used in training. The neural network trained on the full-size images once again had a higher bicep IoU and often did a better job of locating the bicep. Although the cropped network typically had cleaner boundaries around the bicep, which is most obvious in the middle two images of the four examples below, it consistently misidentified extraneous features as the bicep.

Figure 7: Comparison of Validation Image Segmentations.
I hypothesize that the network trained on cropped images does this because it never saw those structures during training, so it cannot use location-based context to learn where the bicep is relative to the rest of the scan. Therefore, I anticipate that this actually caused more confusion due to the similar grayscale value of other muscles instead of minimizing it like I had hoped. Despite the current limitations, these results show promise for using machine learning methods to automatically segment upper arm muscles.
Moving forward, my main goals are to generate a cohesive segmentation of both parts of the humerus using FLoRIN as well as improve the accuracy of the bicep neural network. To segment the outer portion of the humerus, I plan to further tune FLoRIN’s thresholding parameters to separate it from the surrounding muscle. Once the segmentations are post-processed to combine the inner and outer parts of the bone, they have the potential to be used as labels for machine learning methods. As for the bicep neural network, I am in the process setting up a training set with multi-class labels that contain two additional upper arm muscle classes, namely the tricep and brachialis. My hope is that having more features as reference will improve the network’s ability to accurately segment the bicep boundary because these are the three largest muscles in the region of the elbow and forearm [2] and often directly border one another. Further improvement in the identification of the anatomical features within the upper arm has great implications for the future of rehabilitation. Knowledge of shape, size, and arrangement of these attributes can provide insight into how different parts are interrelated, and the ability to gather this information automatically has the potential to save countless hours of manual segmentation.
References:
- Adkins AN, Garmirian L, Nelson CM, Dewald JPA, Murray WM. “Early evidence for a decrease in biceps optimal fascicle length based on in vivo muscle architecture measures in individuals with chronic hemiparetic stroke.” Proceedings from the First International Motor Impairment Congress. Coogee, Sydney Australia, November, 2018.
- Holzbaur, Katherine RS, Wendy M. Murray, Garry E. Gold, and Scott L. Delp. “Upper limb muscle volumes in adult subjects.” Journal of biomechanics 40, no. 4 (2007): 742-749.
- Vidt, Meghan E., Melissa Daly, Michael E. Miller, Cralen C. Davis, Anthony P. Marsh, and Katherine R. Saul. “Characterizing upper limb muscle volume and strength in older adults: a comparison with young adults.” Journal of biomechanics 45, no. 2 (2012): 334-341.
- Shahbazi, Ali, Jeffery Kinnison, Rafael Vescovi, Ming Du, Robert Hill, Maximilian Joesch, Marc Takeno et al. “Flexible Learning-Free Segmentation and Reconstruction of Neural Volumes.” Scientific reports 8, no. 1 (2018): 14247.
I really like it when individuals get together and share thoughts. Great website, stick with it!|