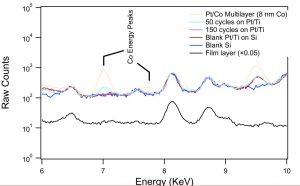
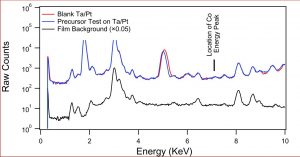
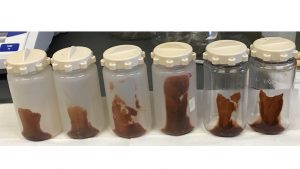
Hi! My name is Josh Werblin and I am a rising junior at Northwestern University studying biomedical engineering. This summer, I have been working in Gyorgy Babnigg’s lab, investigating the applicability of droplet-based microfluidics in obtaining high-quality protein crystals.
He is part of the Midwest Center for Structural Genomics (MCSG, PI: Andrzej Joachimiak) and the Center for Structural Genomics of Infectious Diseases (CSGID, co-directors: Karla Satchell, Andrzej Joachimiak), two structural biology efforts that offer atomic-level insights into the function of proteins and their complexes. Currently, high-quality protein crystals are difficult to generate, and account for one of the major bottlenecks in structural biology. During my summer project, I tested the feasibility of using droplet-based microfluidics to generate crystals amenable for structural studies.
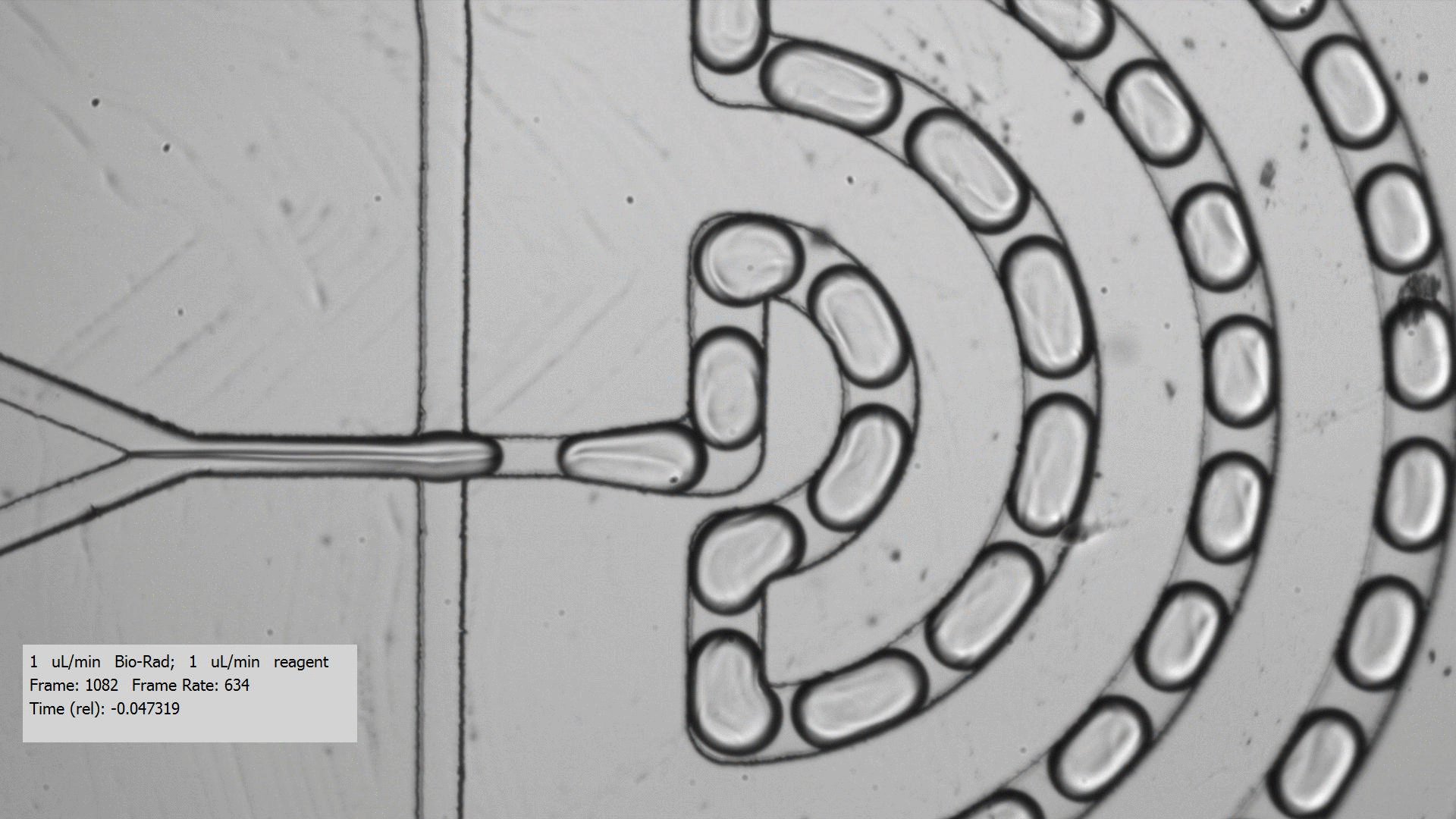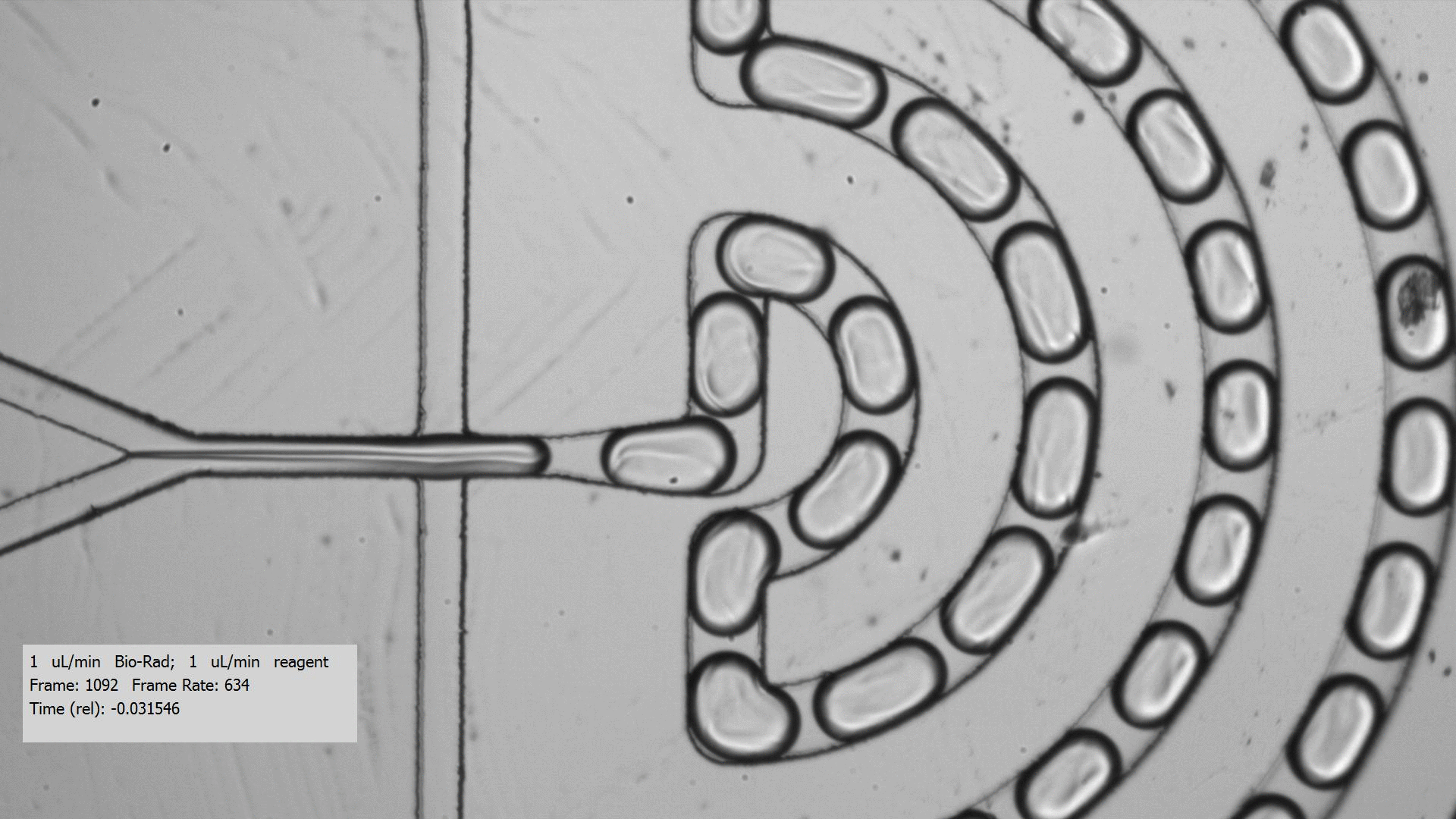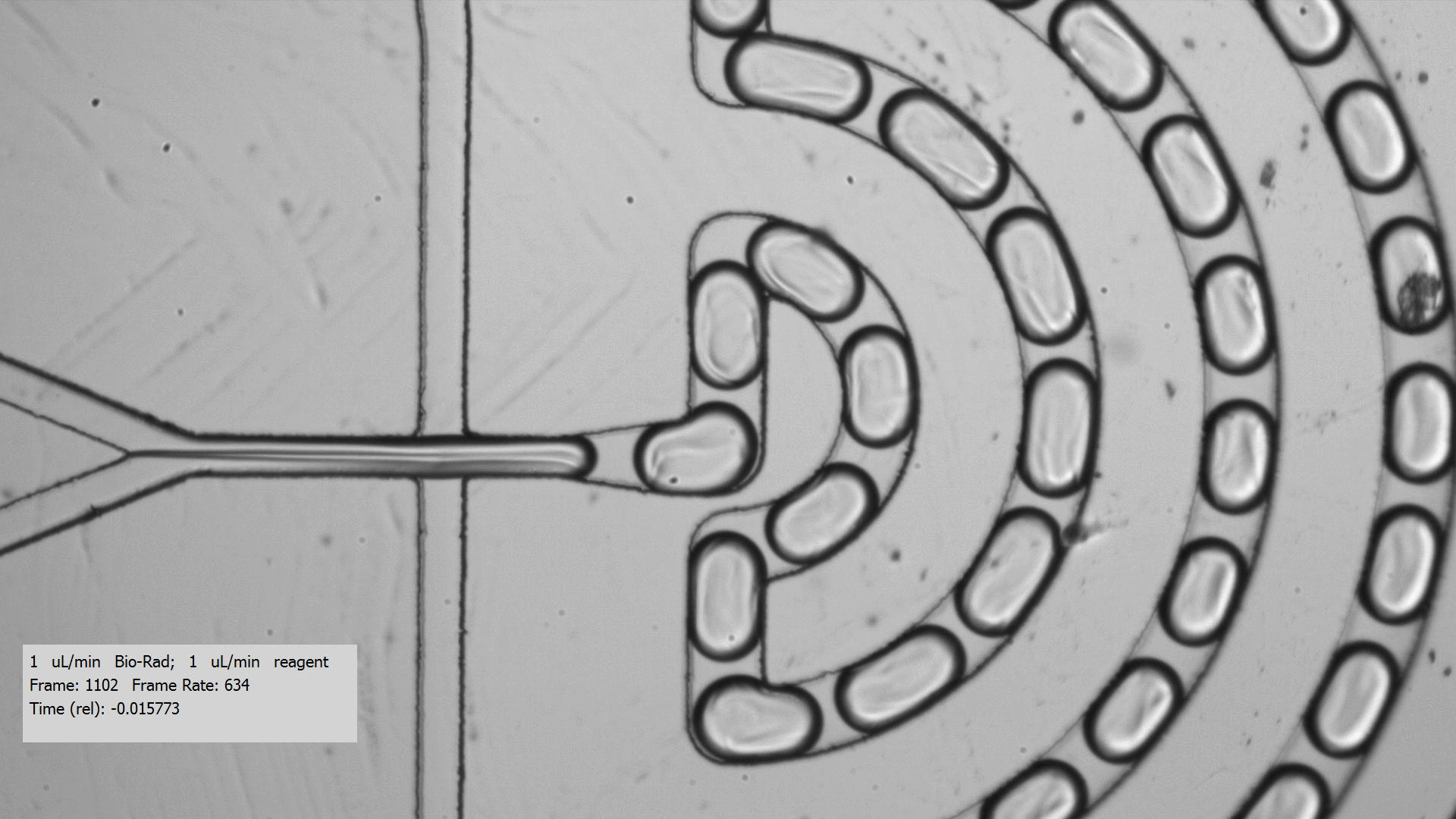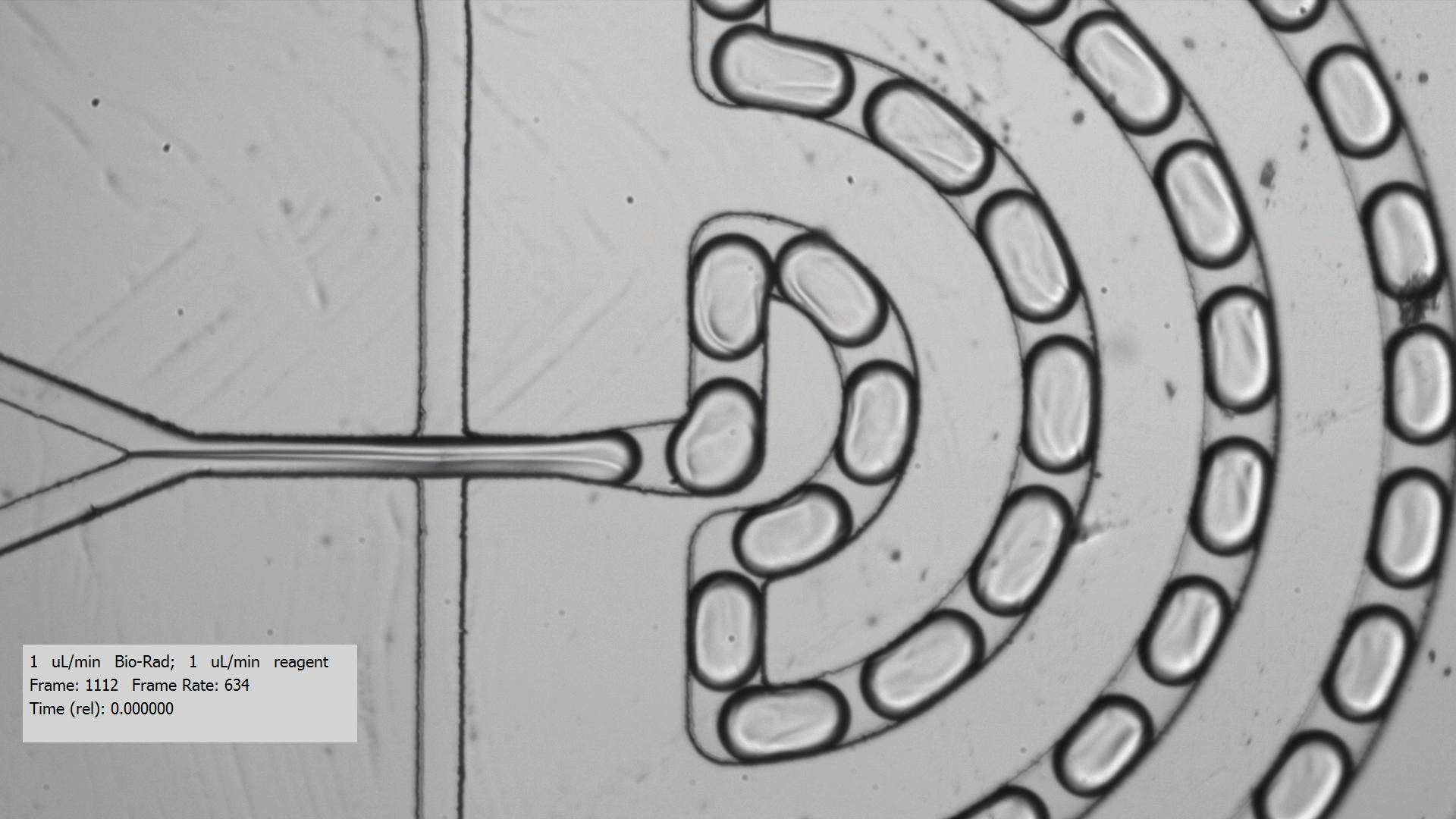
To get crystals to form, you need to combine a purified protein with crystallization screens, which is a set of 96 mix of buffers, salts, and precipitants. Unfortunately, finding the right crystallization condition to make crystals for a protein can take a lot of testing. Even when you figure out a compatible crystallization after testing many crystallization screens and incubation conditions for a protein that yields crystals, the resulting crystals are too tiny for data collection, only a few microns across. Droplet-based microfluidics has the potential to test the many combinations using only small amount of protein for testing.
I tested the crystallization of a previously characterized protein using the microfluidic setting. Small aqueous droplets are formed in fluorinated oil. This can be done by using a small chip and pumping your reagents in. This stream of protein and crystallization screen are cut off by two streams of oil, which creates the droplets.
Using droplet-based microfluidics, I generated tiny droplets containing the protein and crystallization screen at the right concentrations, and was able to grow relatively large crystals (over 50 microns).
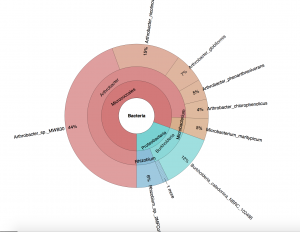
The protein I’ve focused on this summer is an enzyme called sialate O-acetylesterase from one of the good bacteria in our gut (Bacteroides vulgatus). After testing different concentrations and conditions, I finally generated some really good-looking crystals!
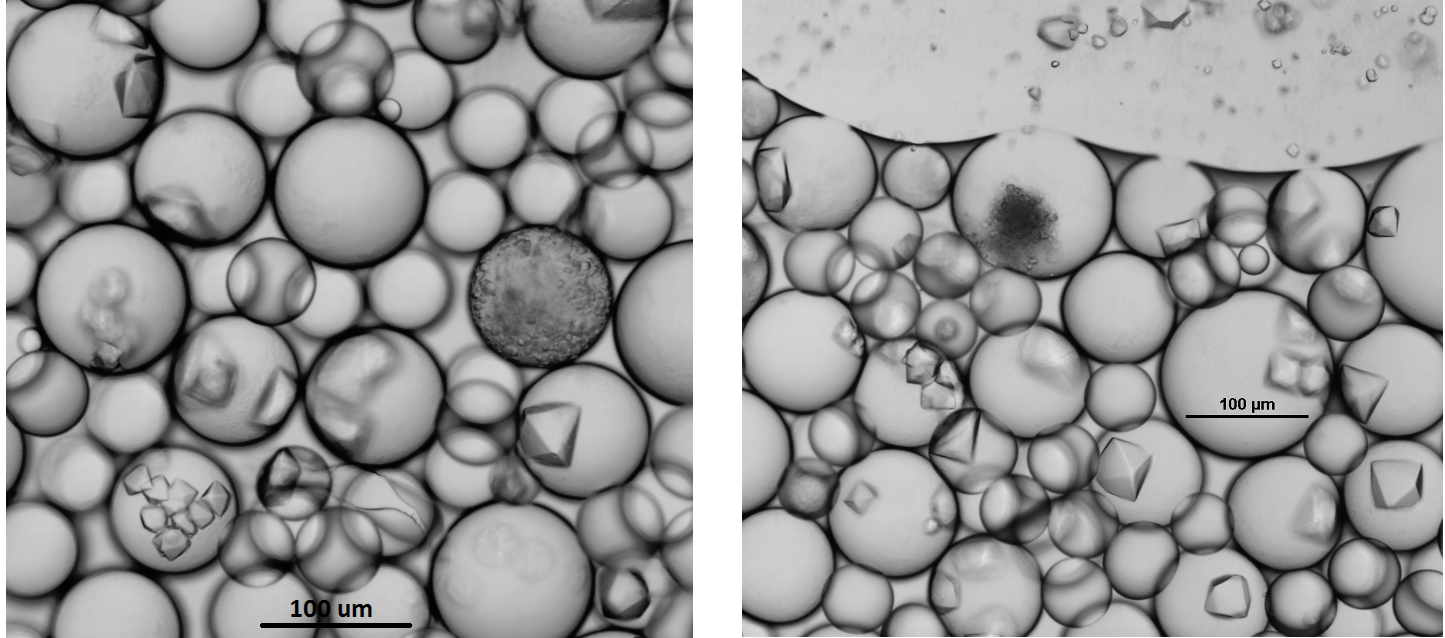
Right: An image of big protein crystals ready to be put onto the beam-line for x-ray crystallography.
With everything all ready, Gyorgy and his colleague, Youngchang Kim, were able to test these crystals at the SBC beam-line of the Advanced Photon Source and hopefully soon I will have the structure of this protein!
I am so thankful to have had this opportunity to work in this lab with wonderful and knowledgeable people and I learned so much about 3D design and printing, experimental design, and proteins and their crystallization.
 This morning the students delivered compelling presentations about their research in a diverse set of areas that have been highlighted on this blog. They did an excellent job communicating the complexities of their work to an audience made up of technical experts in a range of disciplines. This event truly showcased their talents as researchers and communicators.
This morning the students delivered compelling presentations about their research in a diverse set of areas that have been highlighted on this blog. They did an excellent job communicating the complexities of their work to an audience made up of technical experts in a range of disciplines. This event truly showcased their talents as researchers and communicators. 






 They considered how to be persuasive as they convinced their cohorts to join them at a favorite lunch spot. And they practiced delivering their presentations one. word. at. a. time. They also received feedback on their upcoming presentations. We’re grateful to RSG for the visit and great insights and looking forward to student presentations this week at Argonne and early September at Northwestern. Students have the opportunity to showcase their valuable contributions and build bridges to collaborations between Argonne and Northwestern.
They considered how to be persuasive as they convinced their cohorts to join them at a favorite lunch spot. And they practiced delivering their presentations one. word. at. a. time. They also received feedback on their upcoming presentations. We’re grateful to RSG for the visit and great insights and looking forward to student presentations this week at Argonne and early September at Northwestern. Students have the opportunity to showcase their valuable contributions and build bridges to collaborations between Argonne and Northwestern.