Tuning collective I/O strategies for GPFS and Lustre
ROMIO’s strength lies in how it hides the details of the underlying file system from the end-user. MPI_File_open looks the same if you are writing to PVFS or GPFS, even though both systems have very different lower-level interfaces.
When it comes to the venerable but powerful two-phase collective I/O optimization, those file system quirks matter more than we thought. Wei-keng Liao at Northwestern has studied the problem and demonstrated just how badly a “one size fits all” approach is
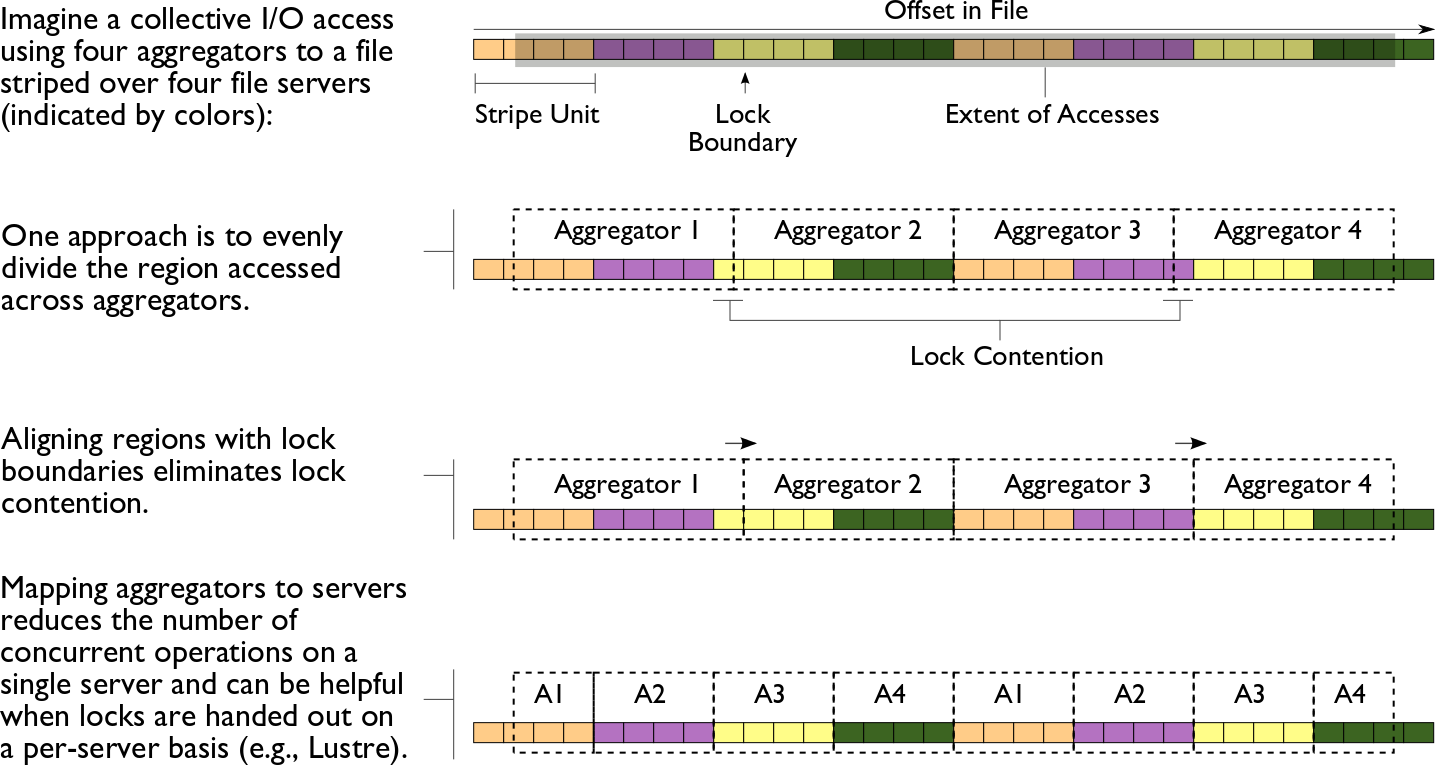
The summary: if you align your ROMIO file domians to file system block boundaries, you get great GPFS performance, but terrible Lustre performance. If you carefully split up your domain into a “group cyclic” style, where each ROMIO I/O aggregator communicates with only one Lustre OSS, you get great Lustre performance, but terrible GPFS performance.
If you try to do this in an application, you are probably going to get it wrong. Let ROMIO deal with it!
Here’s the paper: Dynamically Adapting File Domain Partitioning Methods for Collective I/O Based on Underlying Parallel File System Locking Protocols.