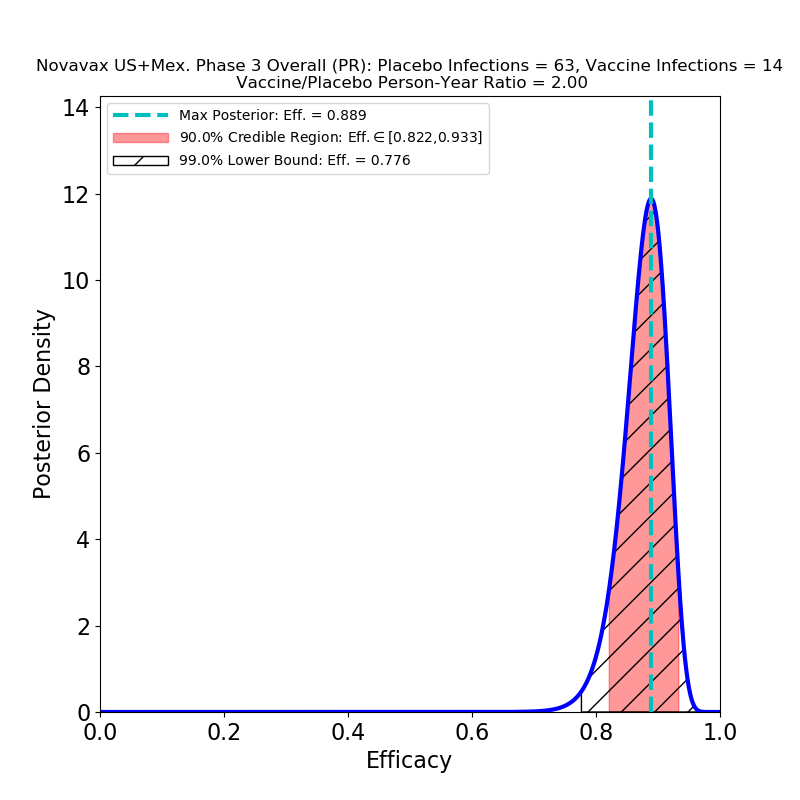
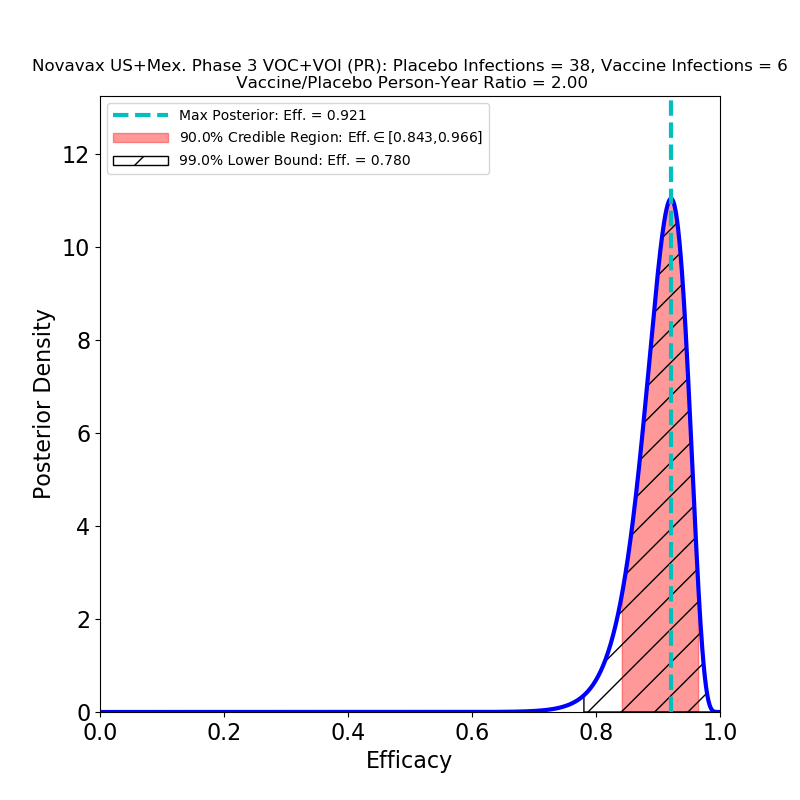
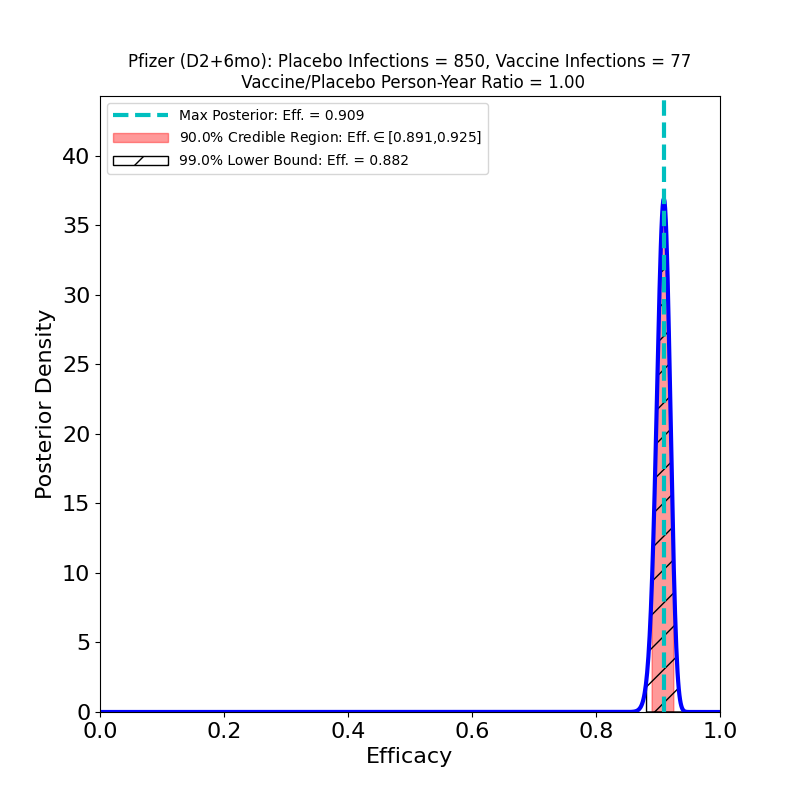
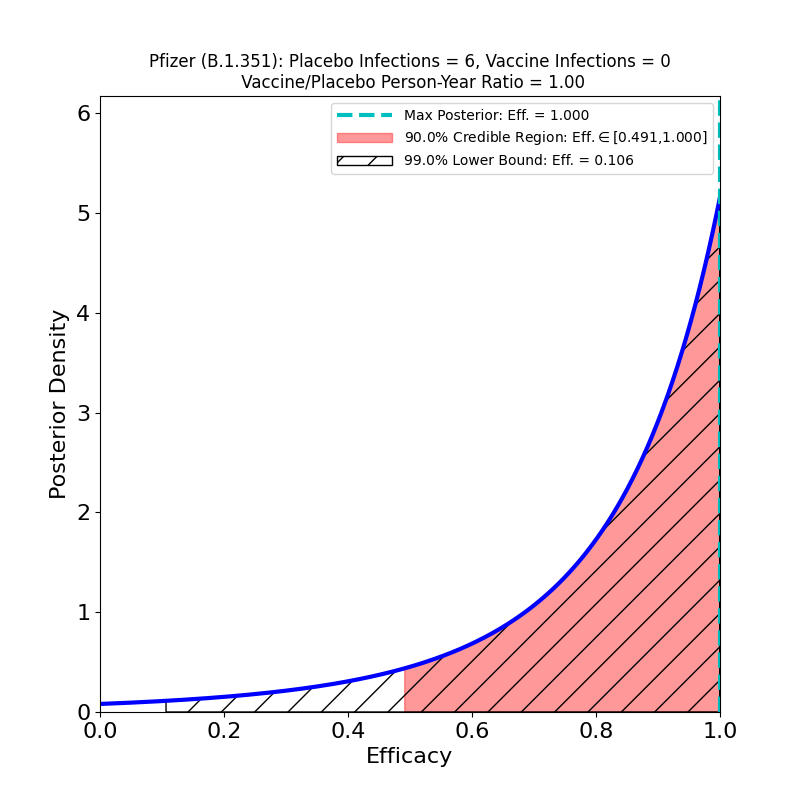
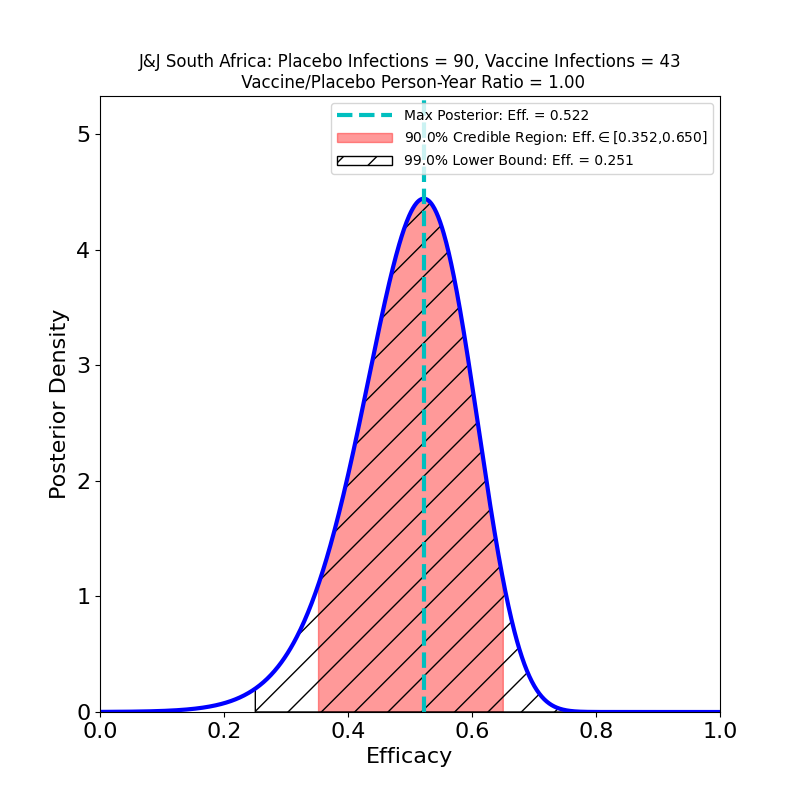
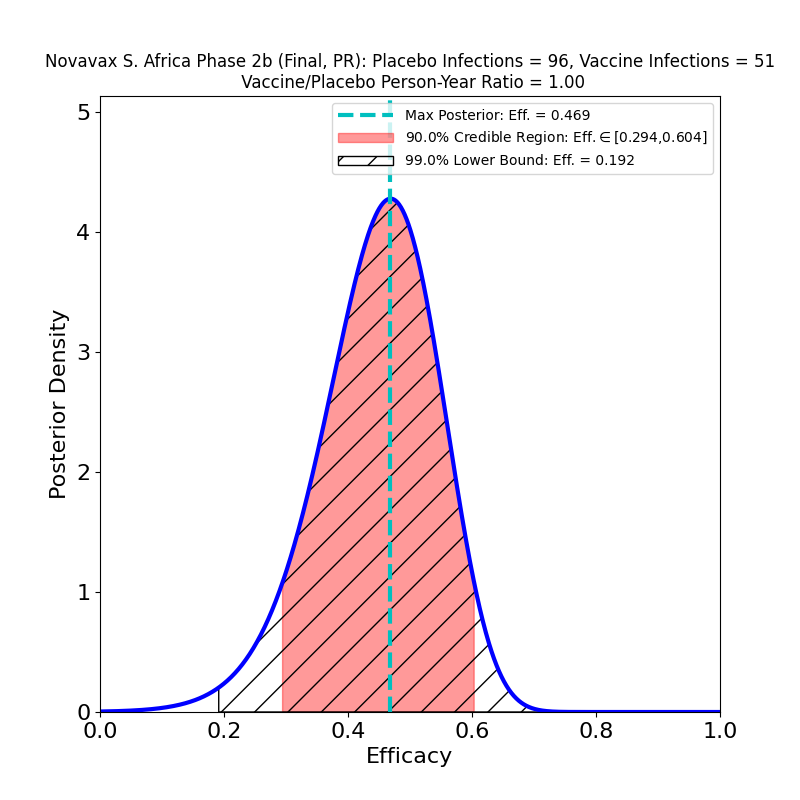
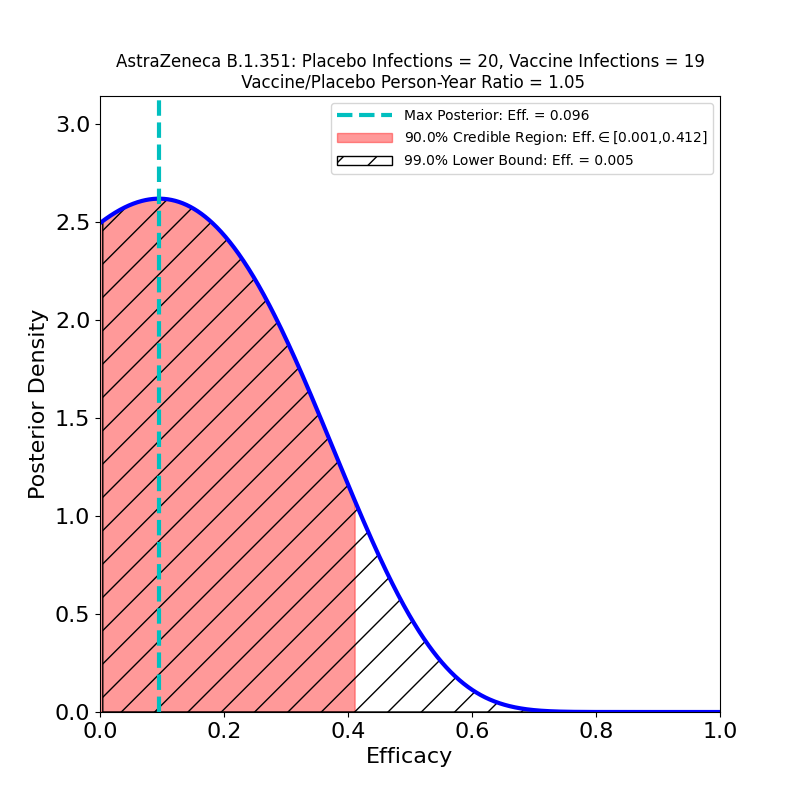
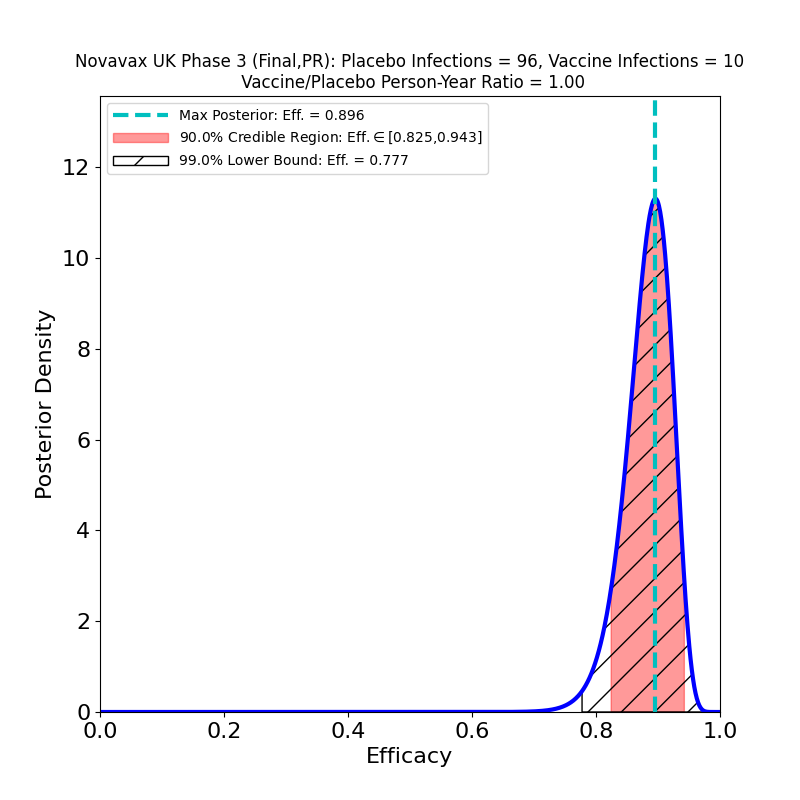
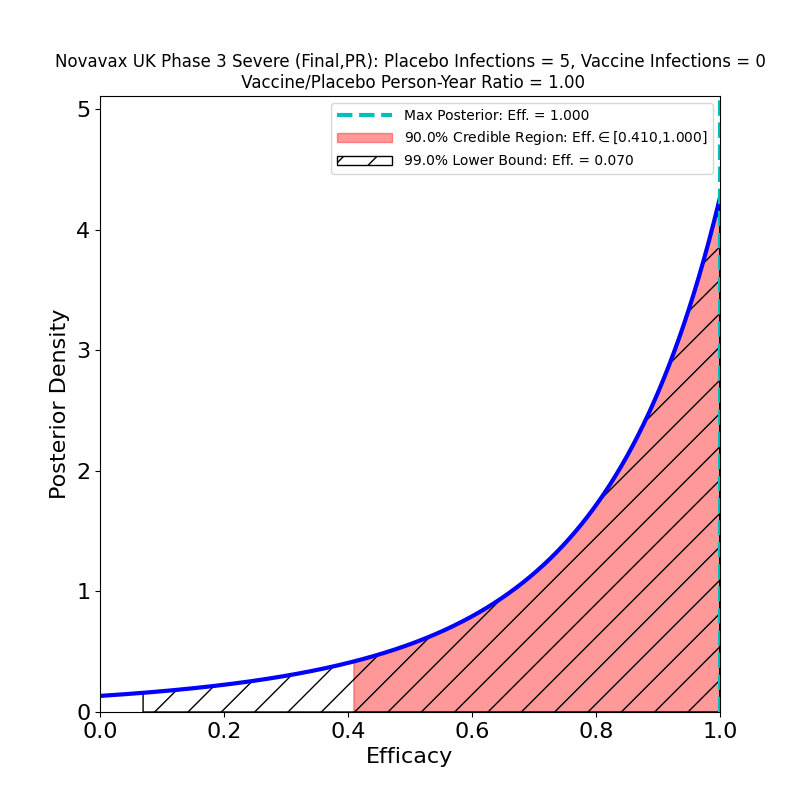
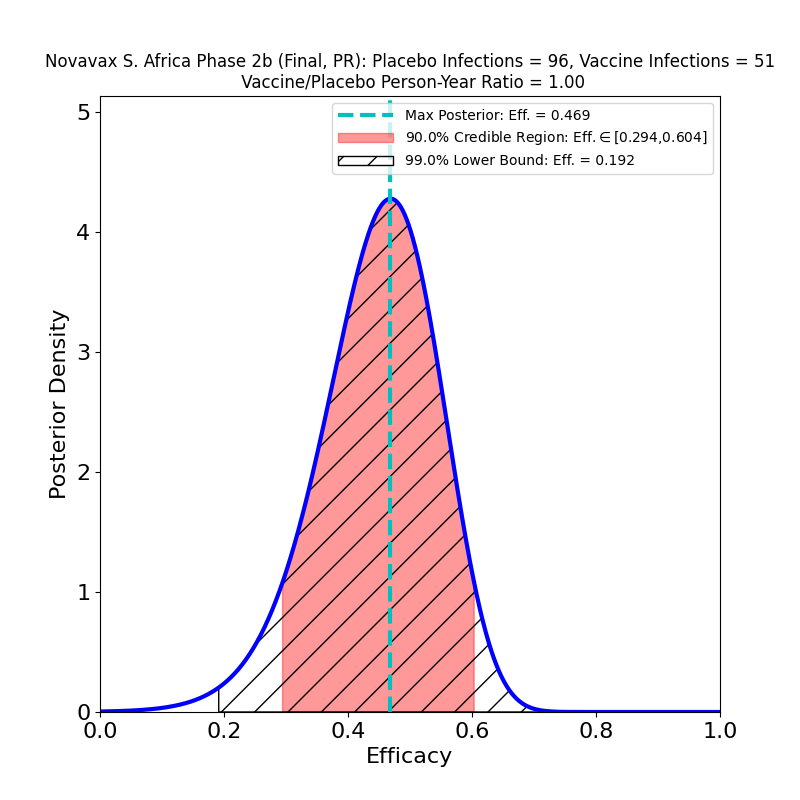
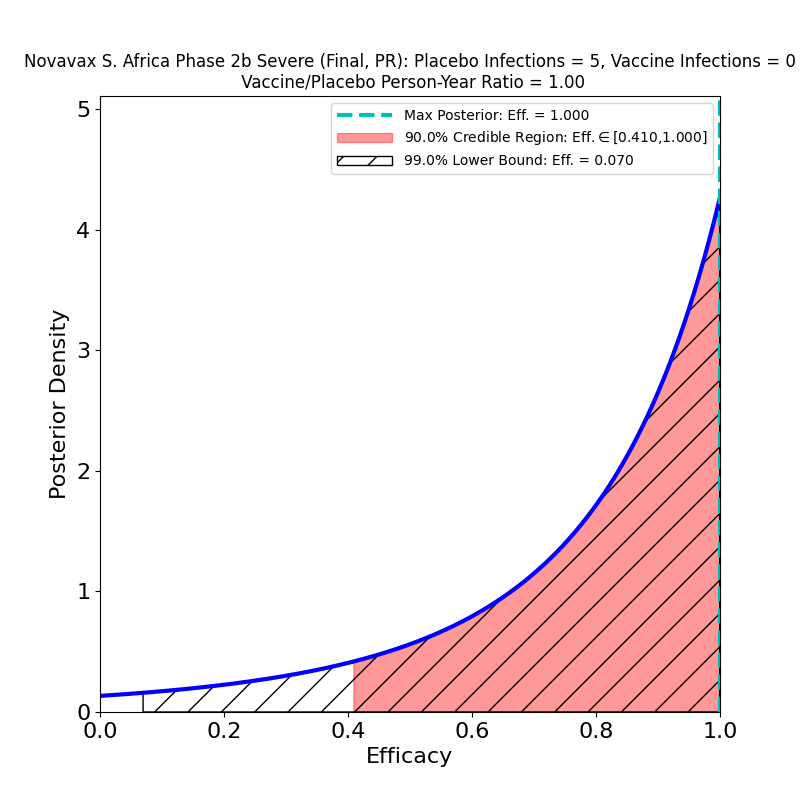
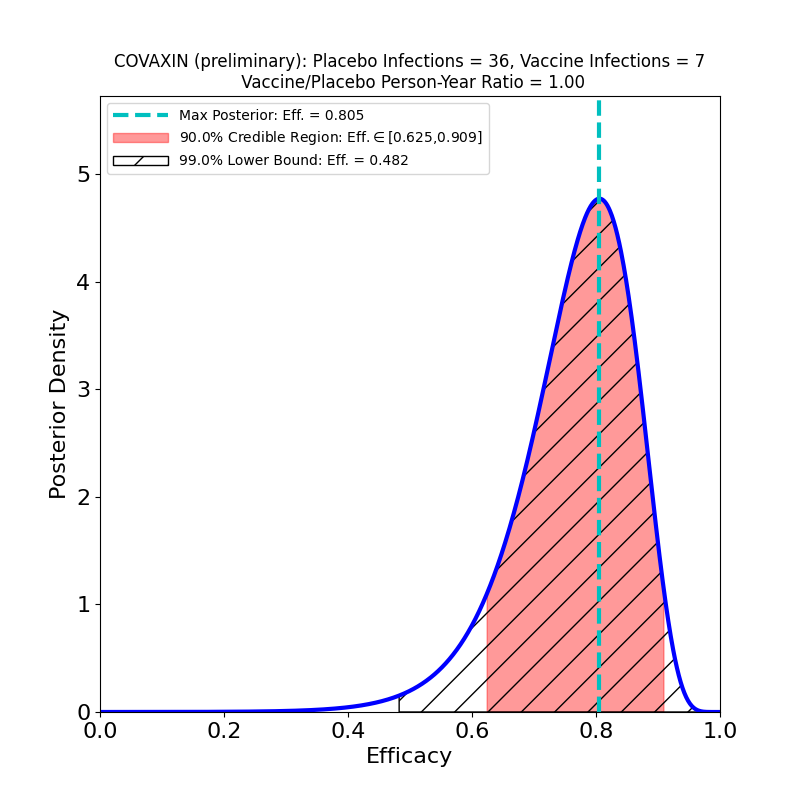
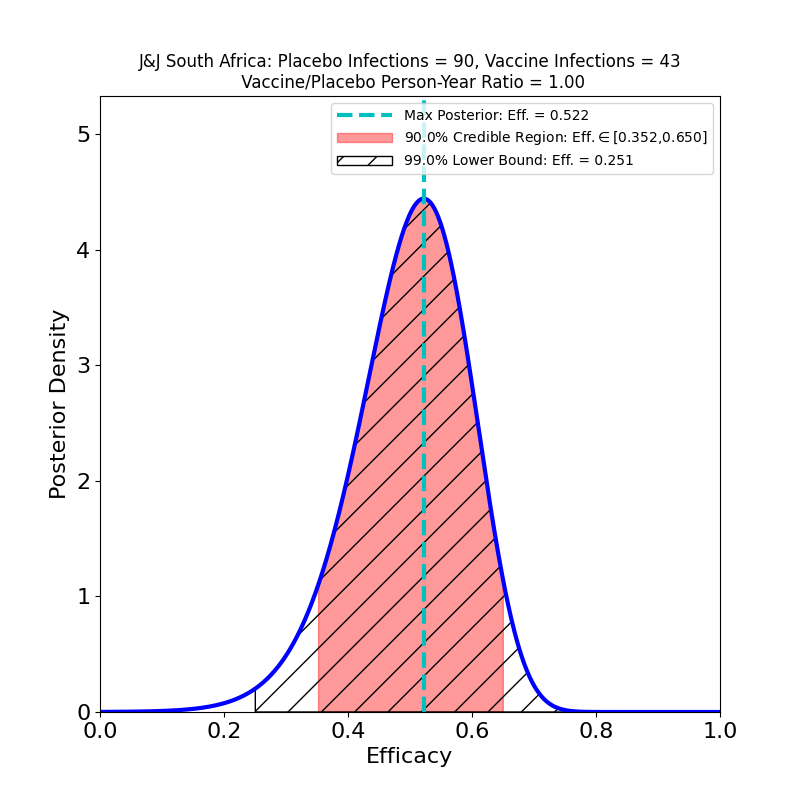
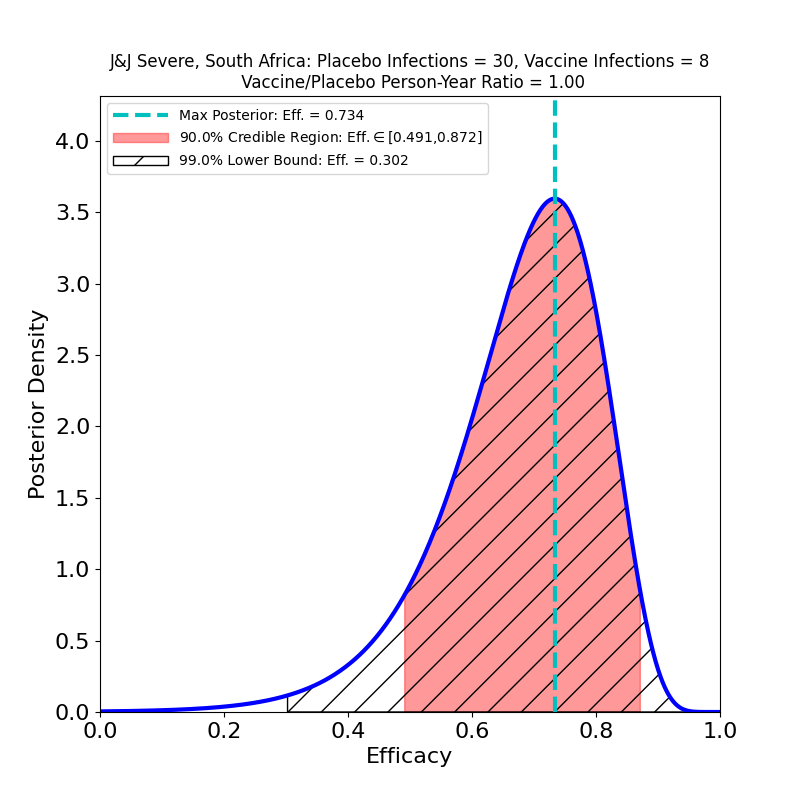
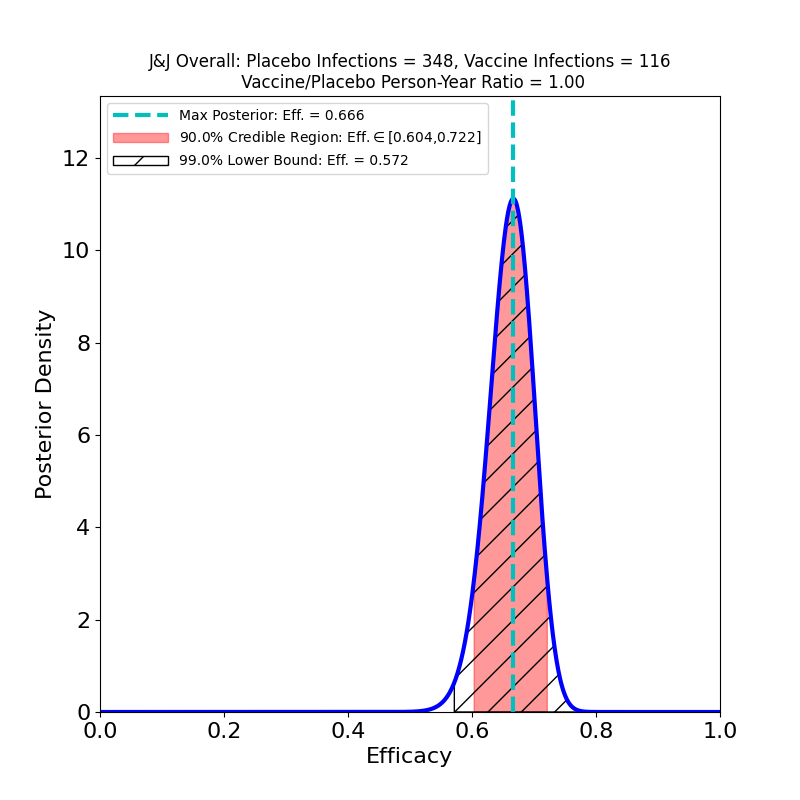
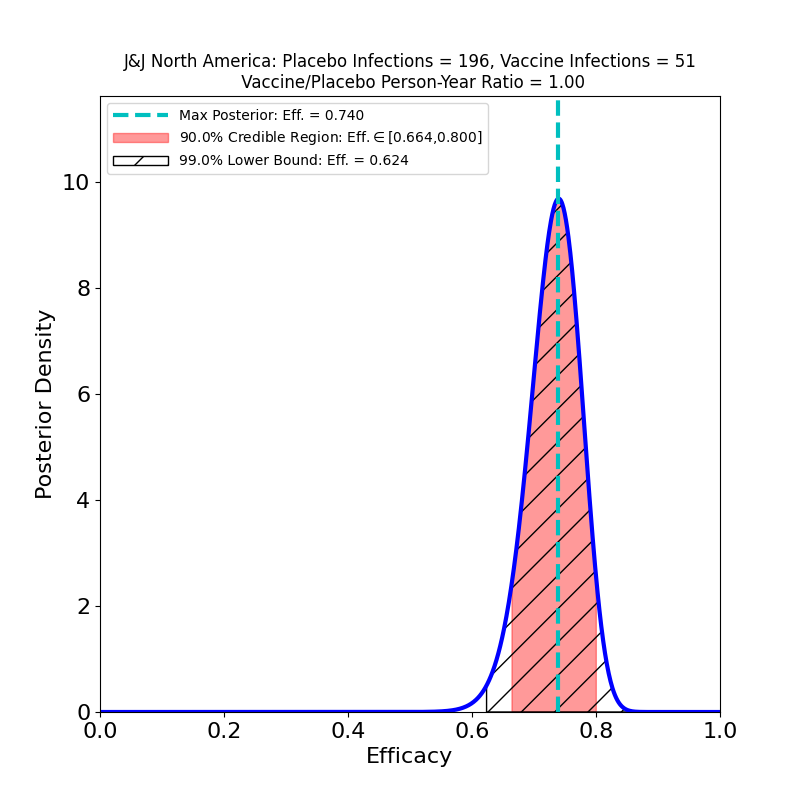
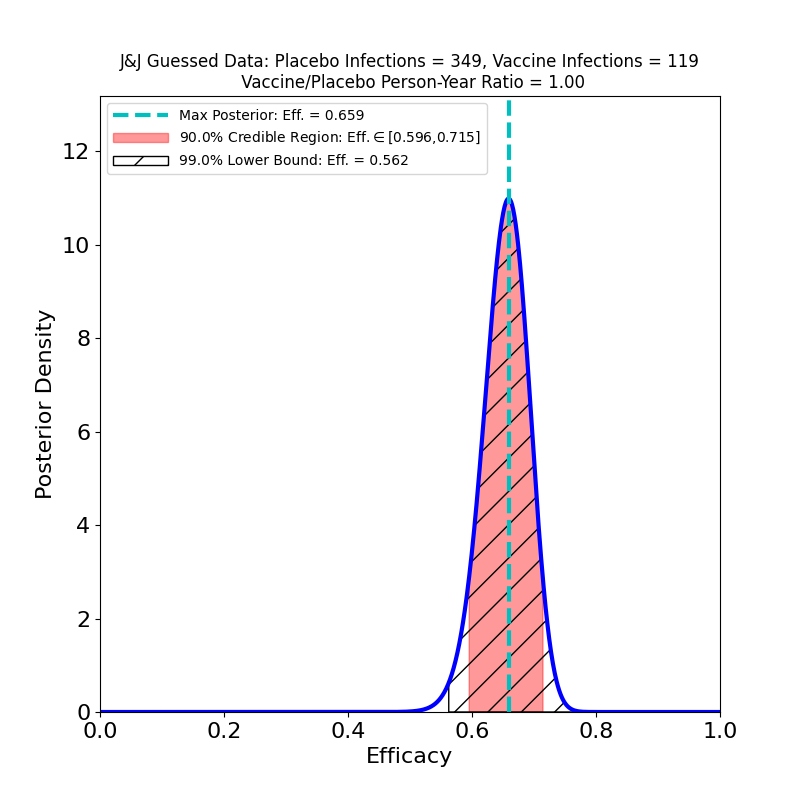
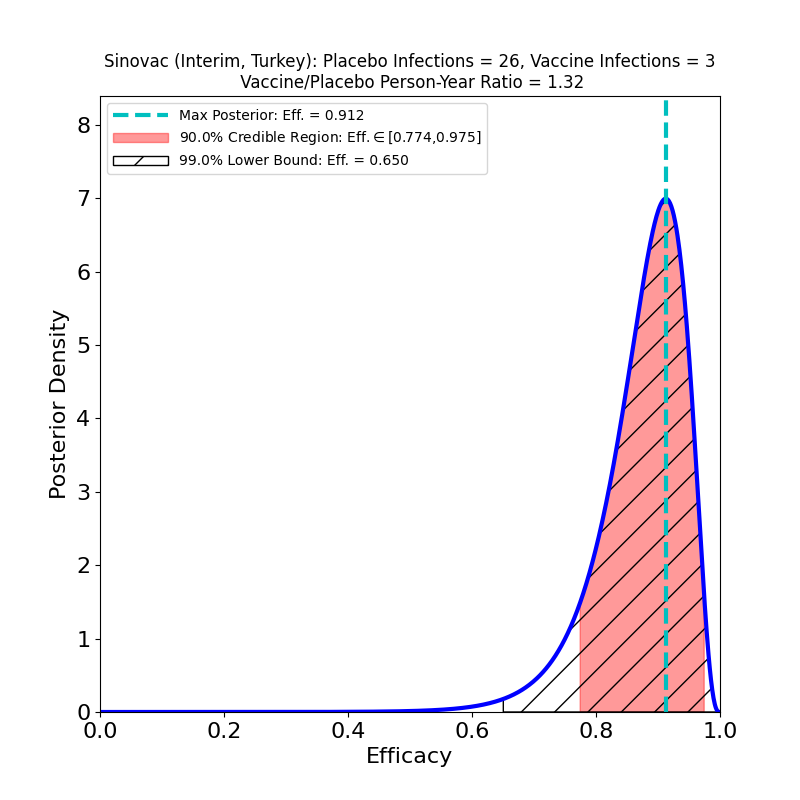
What’s This About?
I haven’t posted a lot about vaccine efficacy lately, largely because the frenzy of vaccine development and clinical trial results basically slowed way down around June 2021, and there hasn’t been that much to write about since on the subject. I’ve been thinking about what to do with this site ever since. Some people do seem to find it useful—there have been nearly 25,000 visitors from all over the world since I started writing about vaccine efficacy, and I hope that those people found information that was valuable to them. To the extent that they did, it makes me somewhat proud, since I am a statistics person rather than a clinically-trained person, so having an impact in the COVID-19 pandemic, however small, feels like an achievement. On the other hand, that same lack of clinical training means that I have to watch myself so as to write things that are justified by data, and keep from making wild, poorly-informed statements that do more harm than good. I feel that so far I’ve stayed on the right side of that line.
I may risk that balance in the next phase of this blog’s development.
I plan to write a few observations of my own on the state of epidemic surveillance, epidemic modeling, and epidemic data, specifically with respect to the COVID-19 epidemic. I am doing this in part because I’ve been more deeply involved in data-driven epidemiological work, especially with respect to vaccine effectiveness (different from efficacy, because it characterized real risk reduction in real populations, rather than “pure” clinical properties of vaccines), culminating in a paper demonstrating the possibilities of large-scale data analytics for epidemic surveillance and vaccine assessment. In the process, I have become somewhat frustrated with the state of data curation and availability, but also with some of the model-premises underlying discussions of subjects such as vaccines, “breakthrough” infections, variants and their potential for vaccine escape, and so on. In my opinion there is a great deal of intellectual confusion about these terms and concepts, and this confusion is feeding needless media and policy panic (and occasionally distracting from necessary panic). I feel I need a place to write down everything that I feel is (usually) subtly or (occasionally) grossly wrong about the public and scientific discussions of these issues. And I happen to have a more-or-less epidemiological blog. So I might as well do it here.
The cost of this change of direction is that I doubt that I can maintain the careful stance of defensible scientific statements that I tried to keep this blog to so far. Quasi-editorials on epidemiology by a statistically well-informed but barely-clinically-literate observer of the field should by no means be taken as authoritative refutations of anything, or in fact as anything more than spurs for further discussion by people working in the field, with whom I would be delighted to engage, and be told in exhausting detail all the reasons why what I’m writing is wrong-headed. I do listen, and try to learn. But I will also argue. I feel that I will have accomplished something useful if I at least bring to light a few unexamined or under-examined assumptions, and occasion a fruitful discussion of those assumptions, even if in the end I am the only one who feels educated by the process.
Nonetheless, I have a strong suspicion that I’ve seen some real issues—defects in how clinical data is created and curated and made available, defects of modeling, catastrophic terminological confusion—that need to be brought into the light. I’ll be discussing these in a series of posts.